AI LLM 모델 성능 비교 사이트 정리 (ChatGPT, Grok3, Claude, Gemini 등)
- LLM의 모델 성능(Benchmark) 점수를 측정하는 다양한 지표들 방법론들이 있지만, AI LLM 모델들의 성능을 한눈에 비교할 수 있는 사이트에 대해서 소개해드리려고 합니다. 개인적으로 제가 가장 자주 사용하는 사이트를 순위대로 적었습니다.
- 1. https://llm-stats.com
2. https://livebench.ai
3. https://web.lmarena.ai/leaderboard
1. llm-stats.com
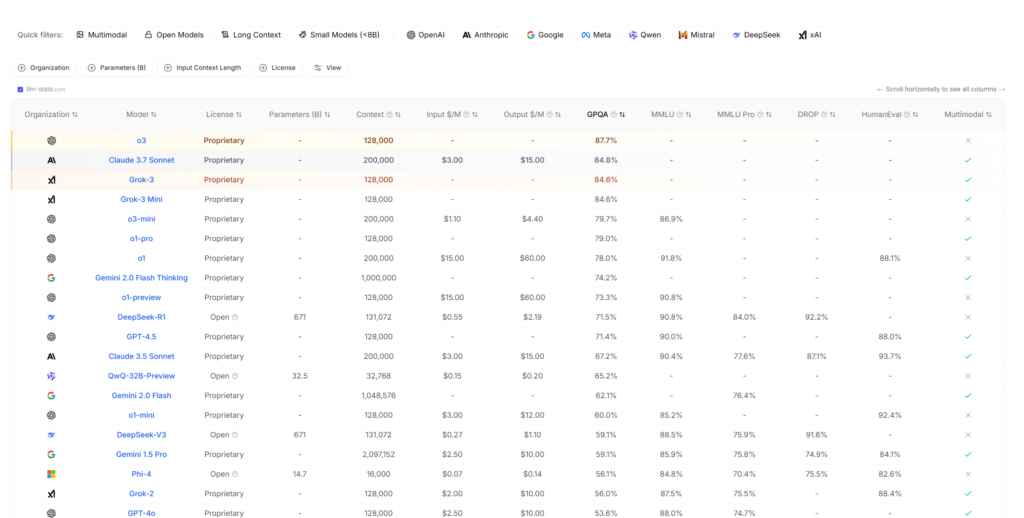
AI 언어 모델(LLM)의 성능(벤치마크) 점수를 비교하여 각 모델별을 table로 만들어 놓은 사이트. 점수를 정리하여 ChatGPT, Grok3, Claude, Gemini 등의 성능을 한눈에 비교하기 쉽게 정리해놓은 사이트 입니다.
사이트 바로가기 링크 : https://llm-stats.com
사이트 접속하시면 스크롤 조금 내리시면 보이는 화면입니다.
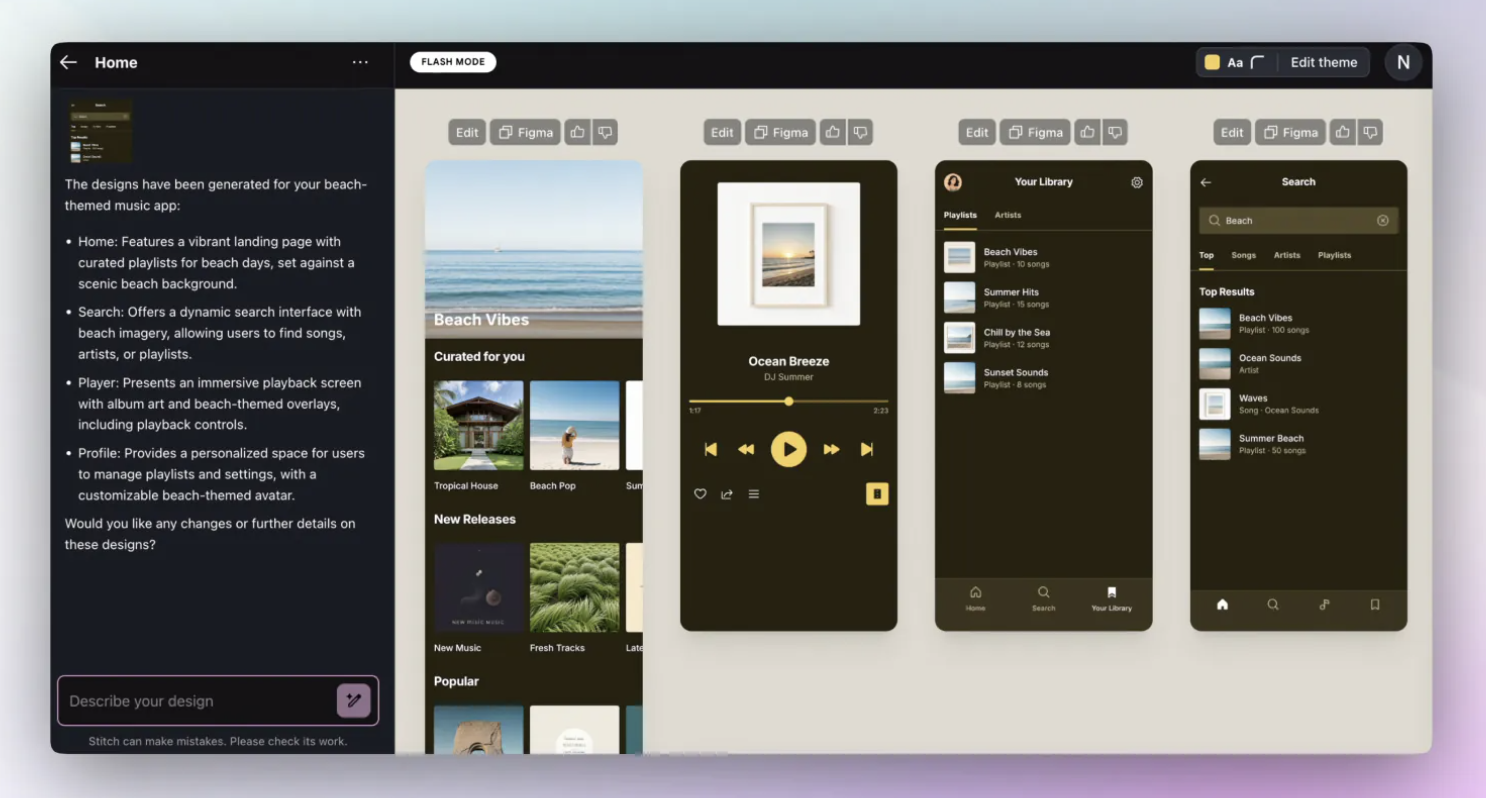
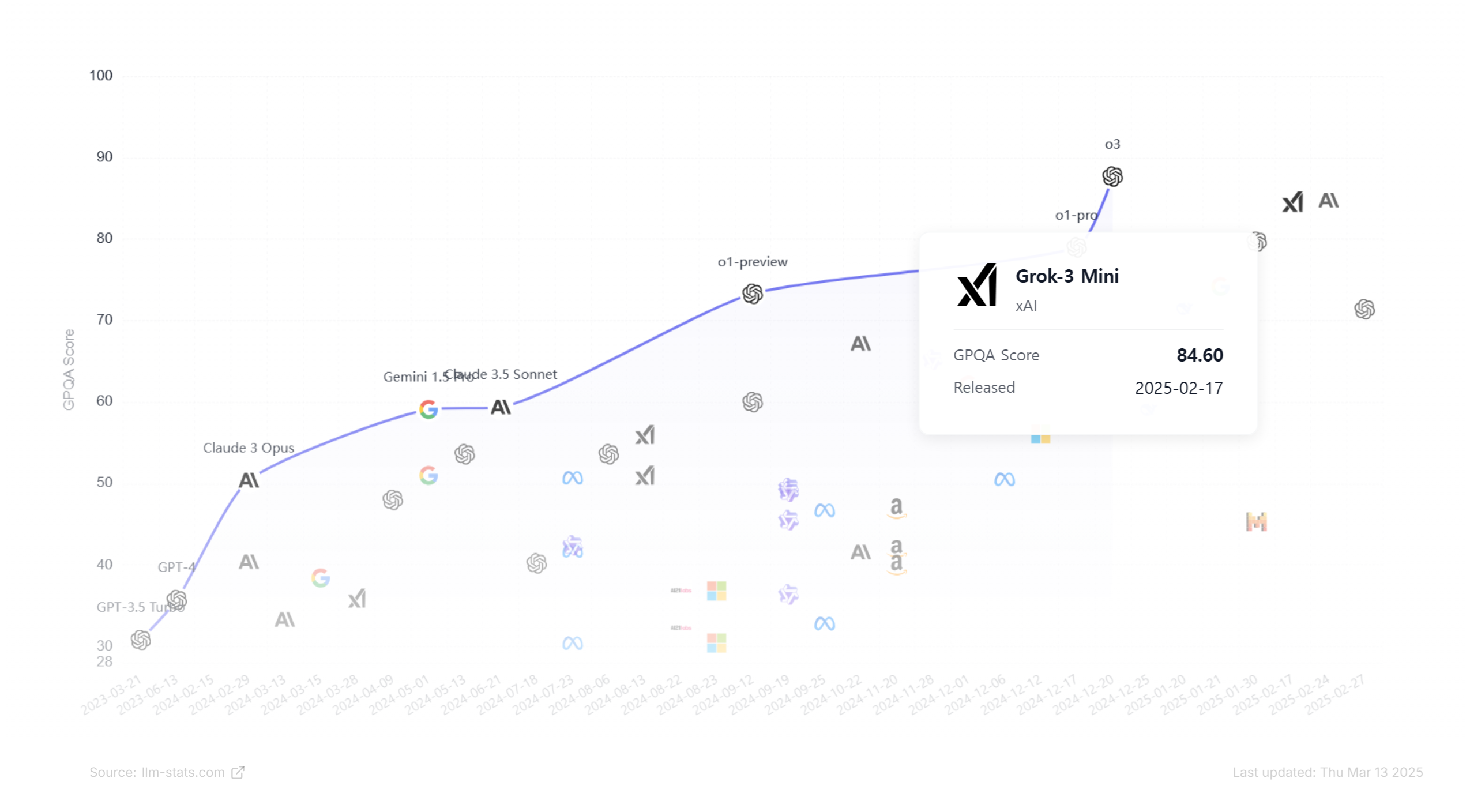
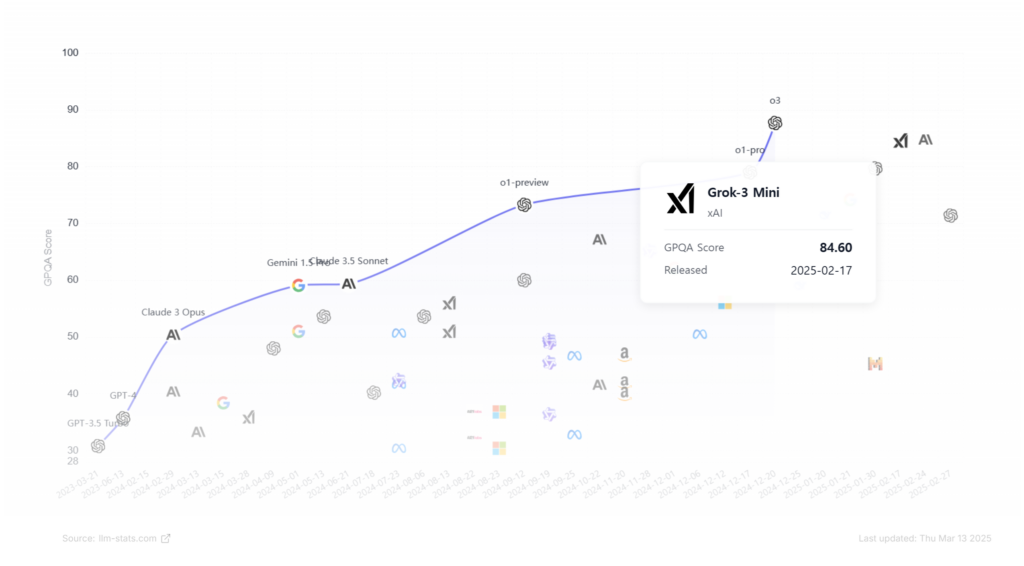
사이트 접속시 맨 상단에 AI LLM 모델들이 출시된 순서(X축)별 성능 점수(Y축)을 한눈에 볼 수 있는 그래프가 나옵니다.(이게 제일 마음에 들어서 1등으로 사용함)
이 사이트는 누가 만들었나?
Reddit에 llm-stats.com 만든 사람이 홍보를 했네요 닉네임 : LocalLLaMA 글 입니다.
해당 글 보러가기 : https://www.reddit.com/r/LocalLLaMA/comments/1h4nz7b/i_built_this_tool_to_compare_llms/
이렇게 홍보하는 모습보니,., 저도 이런 사이트 만들어서 수익화해보고싶네요.
AI LLM 모델별 성능, 벤치마크 결과 (2025년 03월 최신화)
다음 표는 llm-stat.com에 나온 각 모델의 벤치마크 성능을 표 입니다. 모든 점수는 백분율로 표시되며, 높은 값이 더 나은 성능을 의미합니다.
| Organization | Model | License | Parameters (B) | Context | Input $/M | Output $/M | GPQA | MMLU | MMLU Pro | DROP | HumanEval | Multimodal |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OpenAI | o3 | Proprietary | – | 128,000 | – | – | 87.7% | – | – | – | – | ❌ |
| Anthropic | Claude 3.7 Sonnet | Proprietary | – | 200,000 | $3.00 | $15.00 | 84.8% | – | – | – | – | ✅ |
| xAI | Grok-3 | Proprietary | – | 128,000 | – | – | 84.6% | – | – | – | – | ❌ |
| Meta | Llama 3.1 405B Instruct | Open | 405 | 128,000 | $0.90 | $0.90 | 50.7% | 87.3% | 73.3% | 84.8% | 89.0% | ❌ |
| Meta | Llama 3.3 70B Instruct | Open | 70 | 128,000 | $0.20 | $0.20 | 50.5% | 86.0% | 68.9% | – | 88.4% | ❌ |
| Anthropic | Claude 3 Opus | Proprietary | – | 200,000 | $15.00 | $75.00 | 50.4% | 86.8% | 68.5% | 83.1% | 84.9% | ✅ |
| Qwen | Qwen2.5 32B Instruct | Open | 32.5 | 131,072 | – | – | 49.5% | 83.3% | 69.0% | – | 88.4% | ❌ |
| Qwen | Qwen2.5 72B Instruct | Open | 72.7 | 131,072 | $0.35 | $0.40 | 49.0% | – | 71.1% | – | 86.6% | ❌ |
| OpenAI | GPT-4 Turbo | Proprietary | – | 128,000 | $10.00 | $30.00 | 48.0% | 86.5% | – | 86.0% | 87.1% | ❌ |
| Amazon | Nova Pro | Proprietary | – | 300,000 | $0.80 | $3.20 | 46.9% | 85.9% | – | 85.4% | 89.0% | ✅ |
| Meta | Llama 3.2 90B Instruct | Open | 90 | 128,000 | $0.35 | $0.40 | 46.7% | 86.0% | – | – | – | ✅ |
LLM API 가격이 궁금하신분들은 아래 글 클릭
LLM API 비용 총정리 2025년 3월 정보 (ChatGPT, Claude, Gemini, Deepseek 등)
2. web.lmarena.ai/leaderboard
AI 언어 모델(LLM)의 실시간 코딩(realtime coding competition) 성능 비교 사이트입니다.
역시 코딩은 Claude 모델을 이기는 모델이 잘 없네요
사이트 바로가기 링크 : https://web.lmarena.ai/leaderboard
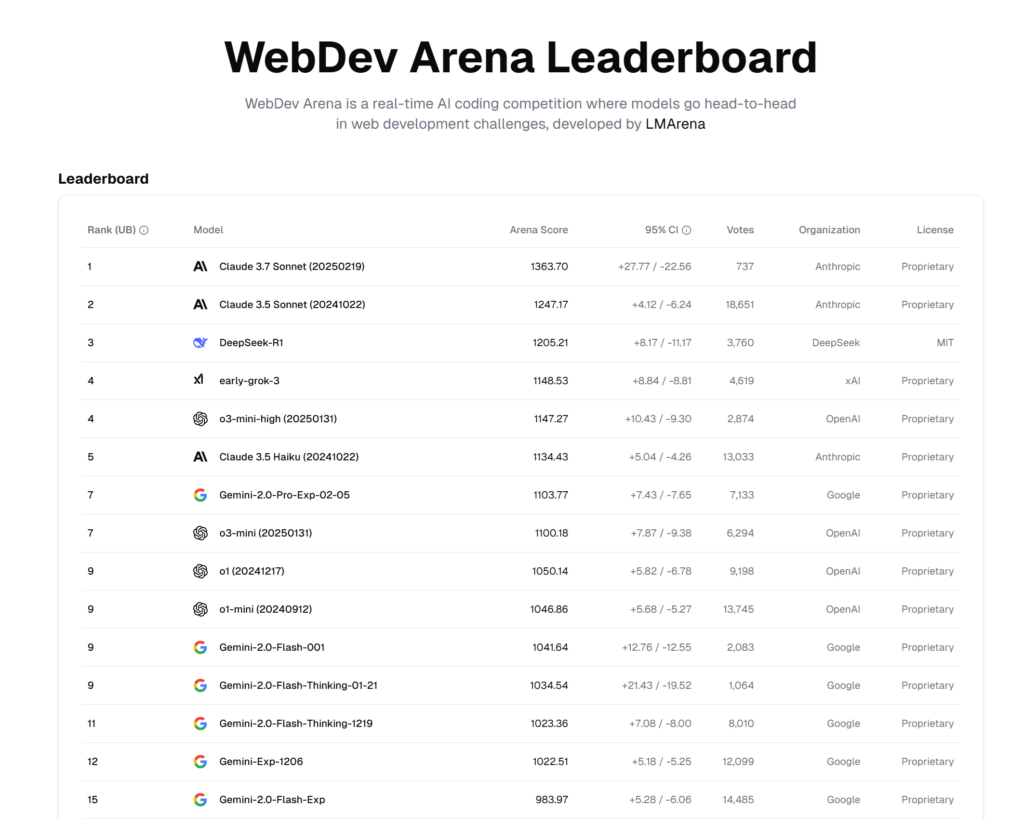
이 사이트를 추천하는 이유는 (1) 최신 모델이 공개되면 3시간 안에 업데이트 된다는 점 입니다. 다양한 LLM AI 성능 비교 사이트가 있지만, 중간에 업데이트가 멈추는게 제일 큰 흠이거든요.
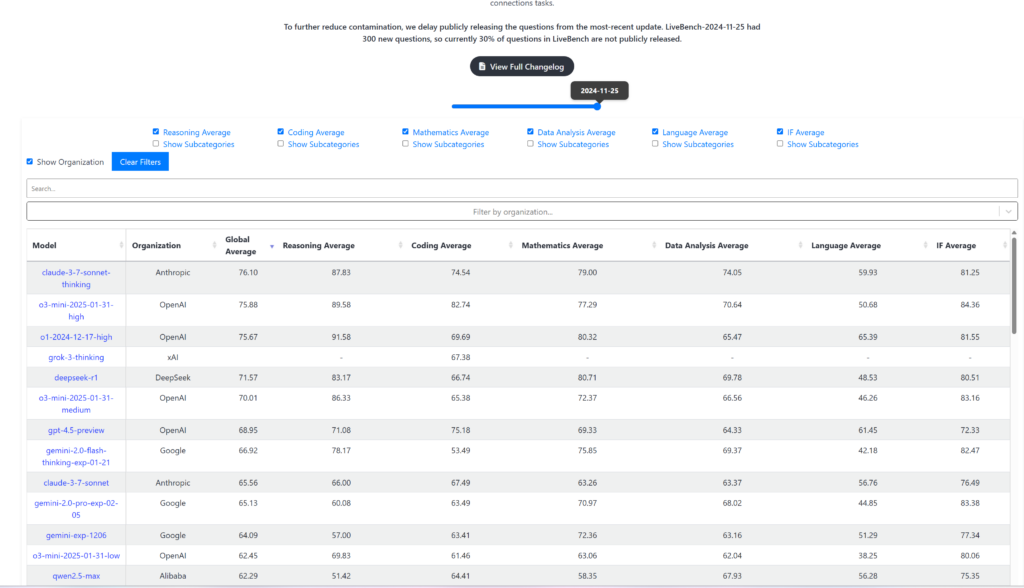
3. livebench.ai
AI 언어 모델(LLM)을 테스트하기 위한 다양한 데이터 셋을 미리 정해놓고 모델들이 새로 나올때 마다 테스트를 하여 점수를 메겨두는 사이트 입니다.
사이트 바로가기 링크 : https://livebench.ai/
추가 정보
- 다른 벤치마크 사이트로는 Vellum AI LLM Benchmark in 2024, YourGPT.ai LLM Leaderboard, Artificial Analysis LLM Leaderboard 등이 있습니다.